正在加载今日诗词....
📌 Powered by Obsidian Digital Garden and Vercel
载入天数...载入时分秒... 总访问量次 🎉
载入天数...载入时分秒... 总访问量次 🎉
Authors:
Tomáš Souček,Prajwal Gatti,Michael Wray,Ivan Laptev,Dima Damen,Josef Sivic
随着生成模型和 LLM 的不断发展,这些技术有望在有些日常的任务和多种场景下能帮助到我们,比如准备一个米其林星级大餐、植物养护等等。这些视觉助手能够对于具体的环境和任务提供相依的指导和反馈。
生成分步文本化的指令和分步视觉指令差别还是很大的,现在的大模型能够很好的生成一些个性化的文本指令。然后简单的将这些指令转为图像或者视频其实很是有很大的挑战的,图像模型一次只能产生一张图像,而视频模型倾向于生成很短的视频片段。而视频指令序列一般是从一个关键帧到另一个关键的的切换。
现有的一些工作是通过综合单个步骤或者没有和用户给定的环境条件结合起来,也就是说这些方法生成了一些看似合理的图像为每一个指令,但是这些图像综合看起来是十分任意的。
本文旨在解决基于用户给定的一张参考图像来生成一系列的视觉指令。论文从指令视频中收集了大量的训练数据,大概包含 4.5M 个图像文本对,并基于这个数据集训练了根据用户参考图像的来生成视觉指令的一个视频生成模型。
首先是从视频旁白中提取出简洁、格式任意的关键步骤,然后将每个步骤和视频中的关键帧相对应,整个工作流的输出是 image-text 的有序序列。这里面的难点在于:互联网上的视频存在噪音很多,并且旁白和视频内容可能对应不上以及视频的外观和旁白口语化带来的多样性和复杂性。为了解决这些问题,作者使用了四阶段的方法:
语音转换: 将视频中的音频根据时间戳转为多个句子。在这一步作者并没有直接使用 YouTube 的 API,而是使用了 SOTA 的语音辨识模型 whisperX 来获得高质量的文本转录。
过滤无关视频: 作者发现上一步得到的视频里面有很多无结构化的片段,比如产品评论等。这部分数据主要是由于基于关键字的爬取数据,并且很容易受到不准确的元数据的干扰。作者使用了一个 LLM 来过滤这些不需要的视频。
步骤提取: 作者观察到一些关键的步骤在视频中经常会被提起,即使和当下的视频内容无法对应。因此,作者使用了 LLM 来叙述中提取结构化的步骤,这些步骤符合 WiKiHow 一步一步指导的格式。在此过程中,作者发现模型不仅仅可以提取到关键的步骤,同时也能够将每一步和对应的时间戳相关联起来,即使跨越了多个叙述片段。
跨模态帧对齐: 对于每个结构化步骤,从视频片段中取出一个最能证明视觉指令的代表帧。作者使用 DFN-CLIP 来计算每个文本指令和其对应的、前后各拓展 15s 的每段视频中每一帧的相似度,选择相似度最高的一个来作为这一步骤的视觉指令代表。

使用上述方法,作者构建了 50w 个指令序列,囊括了 25026 个不同的任务,包括烹饪、家具装修,DIY 手工艺等等。
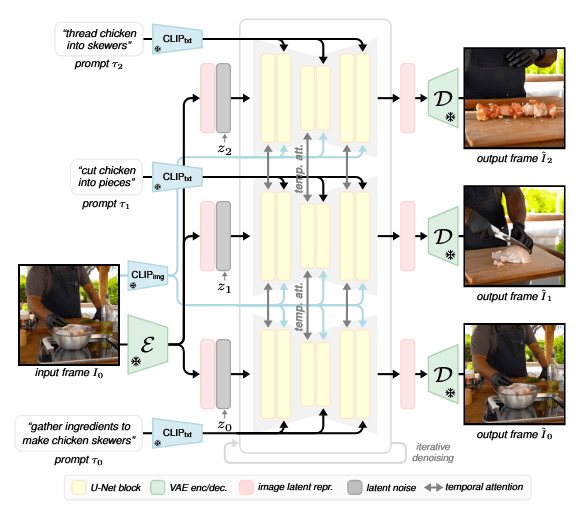
论文中的模型是基于 DynamiCrafter 进行训练的,但重点解决两个问题:如何注入多步骤指令指导以及如何生成长度可变的序列。
输入图像首先通过 VAE encoder 被映射到隐空间,然后被拼接到每帧随机噪声的后面来构成模型的输入。Unet 逐步对输入的 latent 序列进行去噪同时关注所有的图像来确保生成的图像具有时间一致性并跟输入的图像对齐。为了更好地跟输入图像对齐,Unet 还包括 cross-attention 层来关注输入图像的表征。为了指导生成过程朝着希望的视觉序列,序列中的每一帧都通过交叉注意力来关注它所对应的 prompt。
在训练时,用 DynamiCrafter 来初始化模型,与先前固定长度的模型相比,本文的模型是通过变长的视频来实现分布视觉指令生成。在本文中,作者训练时就对序列长度不进行固定而是从数据集中进行采样,如果数据集中的视频长度长于指定的最大值 k,则随机选择起始帧,并使用紧跟的后续帧。